by Michael Letschin, Field CTO
This is the fourth of six posts (the last one was Scale-out) where we’re going to cover some practical details that help raise your SDS IQ and enable you to select the SDS solution that will deliver Storage on Your Terms. The fourth SDS flavor in our series is Hyperconverged “SDS”.
Hyperconverged systems are the subject of much industry hype and analyst debate. Some consider hyperconverged systems to be a form of SDS, others keep them out of the category for not having software-only options. What to know: a hyperconverged system is a single integrated hardware and software system comprising multiple head nodes that present all storage as one virtual pool (think Nutanix or VMware’s EVO Rail). This means that some of the software-only SDS benefits – like flexibility and cost effectiveness – are severely limited.
That said, because it’s fast and easy to set up and drop in a hyperconverged system, it’s a good choice for branch offices or green-field deployments, where there are no existing storage systems to integrate with. Hyperconverged systems are somewhat of a “black box”– meaning you’re not going to have access to software to tune – but you can dial up the performance by increasing the number of nodes.
The downside of Hyperconverged “SDS” is that it’s difficult to impossible to change the system later. Hyperconverged “SDS” provides building block only. You buy what the vendor is selling, which narrows your options. Because you’re tied to a vendor and their pricing models, cost efficiency is also limited. Plus, you’ll need to buy equal amounts of storage and compute capacity. Unless you’re an organization where requirements for storage and compute capacity scale in perfect step, this means you’ll end up with too much of one or the other, wasting part of your investment.
Overall grade: C
See below for a typical build and the report card:



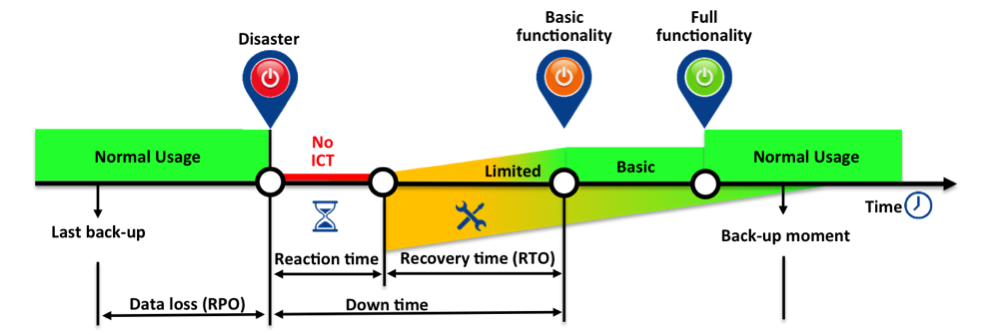
 In this digital era we are using and creating more data than ever before. To put this into perspective, the last two years we created more data than all years before combined! Social media, mobile devices and smart devices combined in internet of things (IoT) accelerate the creation of data tremendous. We use applications to work with different kind of data sources and to help us streamline these workloads. We create valuable information with the available data by adding context to it. A few examples of data we use, store and manage are: documents, photos, movies, applications and with the uprise of virtualization and especially the Software Defined Data Center (SDDC) also complete infrastructures in code as a backend for the cloud. In the last two years we created more data worldwide, than all digital years before!
In this digital era we are using and creating more data than ever before. To put this into perspective, the last two years we created more data than all years before combined! Social media, mobile devices and smart devices combined in internet of things (IoT) accelerate the creation of data tremendous. We use applications to work with different kind of data sources and to help us streamline these workloads. We create valuable information with the available data by adding context to it. A few examples of data we use, store and manage are: documents, photos, movies, applications and with the uprise of virtualization and especially the Software Defined Data Center (SDDC) also complete infrastructures in code as a backend for the cloud. In the last two years we created more data worldwide, than all digital years before!