
By Edwin Weijdema, Sales Engineer Benelux & Nordics
Why do we build ICT infrastructures? What is the most important part in those infrastructures? It is Data! With the digital era we need to store bits of information, or so called data, so we can process, interpreter, organize or present that as information by providing context and adding value to the available data. By giving meaning and creating context around data we get useful information. We use data carriers to protect the precious data against loss and alteration. Exchanging floppies/tapes with each other was not that efficient and fast. So storage systems came into play, to make it easier to use, protect and manage data.
Networks and especially the internet connects more and more data and people. Designing and sizing storage systems that hold and protect our data can be a bit of a challenge, because there are several different dimensions you should take into consideration while designing and sizing your storage system(s). In the Three Dimensions of Storage Sizing & Design blog series we will dive deeper into the different dimensions around storage sizing and design.
Use
 In this digital era we are using and creating more data than ever before. To put this into perspective, the last two years we created more data than all years before combined! Social media, mobile devices and smart devices combined in internet of things (IoT) accelerate the creation of data tremendous. We use applications to work with different kind of data sources and to help us streamline these workloads. We create valuable information with the available data by adding context to it. A few examples of data we use, store and manage are: documents, photos, movies, applications and with the uprise of virtualization and especially the Software Defined Data Center (SDDC) also complete infrastructures in code as a backend for the cloud. In the last two years we created more data worldwide, than all digital years before!
In this digital era we are using and creating more data than ever before. To put this into perspective, the last two years we created more data than all years before combined! Social media, mobile devices and smart devices combined in internet of things (IoT) accelerate the creation of data tremendous. We use applications to work with different kind of data sources and to help us streamline these workloads. We create valuable information with the available data by adding context to it. A few examples of data we use, store and manage are: documents, photos, movies, applications and with the uprise of virtualization and especially the Software Defined Data Center (SDDC) also complete infrastructures in code as a backend for the cloud. In the last two years we created more data worldwide, than all digital years before!
Workloads
To make it easier and faster to work with data, applications have been created. Today we use, protect and manage a lot of different kind of workloads that run on our storage systems. The amount of work that is expected to be done in a specific amount of time, has several characteristics that defines the workload type.
- Speed– measured in IOPS (Input/Output Per Second), defines the IOs per second. Read and/or Write IOs can be of different patterns (for example, sequential and random). The higher the IOPS the better the performance.
- Throughput– measured in MB/s, defines data transfer rate also often called bandwidth. The higher the throughput, the more data that can be processed per second.
- Response– measured in time like ns/us/ms latency, defines the amount of time the IO needs to complete. The lower the latency the faster a system/application/data responds, the more fluid it looks to the user. There are many latency measurements that can be taken throughout the whole data path.
It is very depended on the type of workload which characteristic is the most important metric. For example stock trading is very latency dependent, while a backup workload needs throughput to fit within a back-up window. You can size and design the needed storage system if the workloads are known that will be using the storage system(s). Knowing what will use the storage is the first dimension for sizing and designing storage systems correctly.
Protect
A key factor to use storage systems for, is to protect the data we have. We must know the level of insurance the organization and users need/are willing to pay for, so we can design the storage system accordingly. We need to know the required usable capacity combined with the level of redundancy so we can calculate the total amount of capacity needed in the storage system. Always ask yourself do you want to protect against the loss of one system, entire data centers or even across geographic regions, so you can meet the availability requirements.
- Capacity– measured in GB/TB/PB or GiB/TiB/PiB. The amount of usable data we need to store on the storage and protect.
- Redundancy– measured in number of copies of the data or meta data which can rebuild the data to original. e.g. measures like for instance parity, mirroring, multiple objects.
- Availability– measured in RTO and RPO. The maximum amount of data we may lose called the Recovery Point Objective (RPO) and the maximum amount of time it takes to restore service levels Recovery Time Objective (RTO).
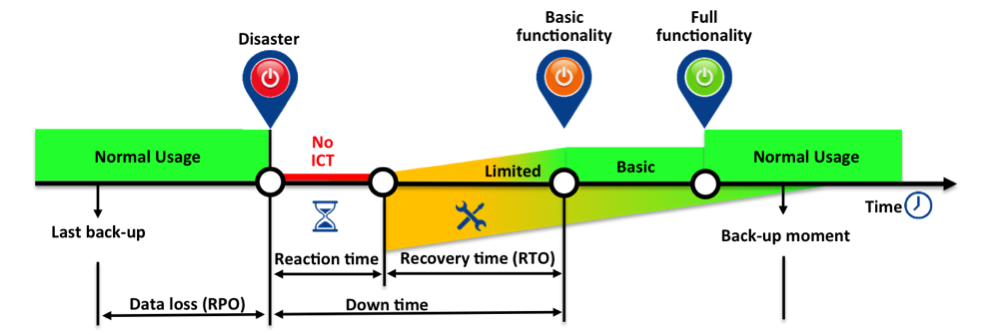
Knowing how much data we must protect, against defined protection/service levels (SLA’s), gives us the second dimension for sizing and designing the storage system correctly.
Manage
Working with storage systems and designing them takes some sort of future insight or like some colleagues like to call it: a magic whiteboard. How is the organization running, where is it heading towards and what are the business goals to accomplish. Are business goals changing rapidly or will it be stable for the next foreseeable future? That are just a few examples of questions you should ask. Also a very important metric is the available budget. Budgets aren’t limitless so designing a superior system that is priceless will not work!
- Budget– an estimate of income and expenditure for a set period of time. So whats the amount of money that can be spend on the total solution and if departments are charged whats the expected income and how is that calculate, e.g. price per GB/IOPS/MB, price per protection level (SLA’s) or a mix of several. Also specific storage efficiencies features, that reduce the amount of data, should be taken into account.
- Limitations– know the limitations of the storage system you are sizing and designing. Every storage system has a high-watermark where performance gets impacted if the storage system fills up beyond that point.
- Expectations– How flexible should the system be and how far should it scale?
Its all about balancing cost and requirements and managing expectations to get the best possible solution, within the limitations of the storage system and/or organization. Managing the surroundings of the proposed storage solution gives us the third and final dimension for sizing and designing storage systems.
Overview
Sizing and designing storage systems is, and will always be, a balancing act about managing expectations, limitations and available money to get the best possible solution. So the proposed workloads will run with the correct speed, throughput and responsiveness while full-filling the defined availability requirements. With the uprise of clouds and Infrastructures as a Service (IaaS) vendors, organizations just tend to buy a service. Even if that’s the case it helps tremendous selecting the correct service when you understand how your data is used, against which protection levels so you can manage that accordingly.
To get the best bang for your buck its helps to understand how to determine the three dimensions correctly, so you can size & design the best solution possible. In the next parts of this blog series we will dive deeper into the three dimensions of storage sizing & design: Use, Protect and Manage. In part 2 we will dive into the first Dimension Use with determining workloads.